„Einfache Tabellen“ beziehen sich auf tabellarische Daten ohne zusammengefasste Zellen, mit einer einzigen Primaerschluessel-Spalte mit eindeutigen Elementen, eindeutigen und aussagekraeftigen Spalten- oder Zeilentiteln und einer klaren Spalten- oder Zeilen-Spalten-Struktur. Beispiel für eine reine Spaltentabelle:
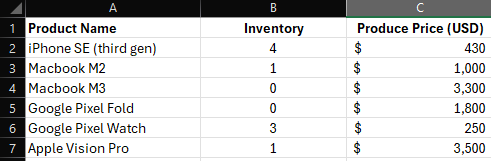

Wenn diese überschritten wird, laeuft das Training in einen Fehler. Stand Maerz 2024 betraegt das Maximum ca. 8000 Tokens pro Zeile (inklusive des JSON-Codes, der zum Darstellen der Tabellenstruktur erforderlich ist).
Das bedeutet, dass der tatsaechliche Anteil für Werte geringer ausfaellt und von der Laenge von Spalten- und Zeilennamen abhaengt. Wenn Ihre Daten dem oben beschriebenen Format entsprechen, koennen Sie Ihre Tabelle als Trainingsquelle hochladen.
Dazu gehen Sie zu: Sources → Add Sources → Tables
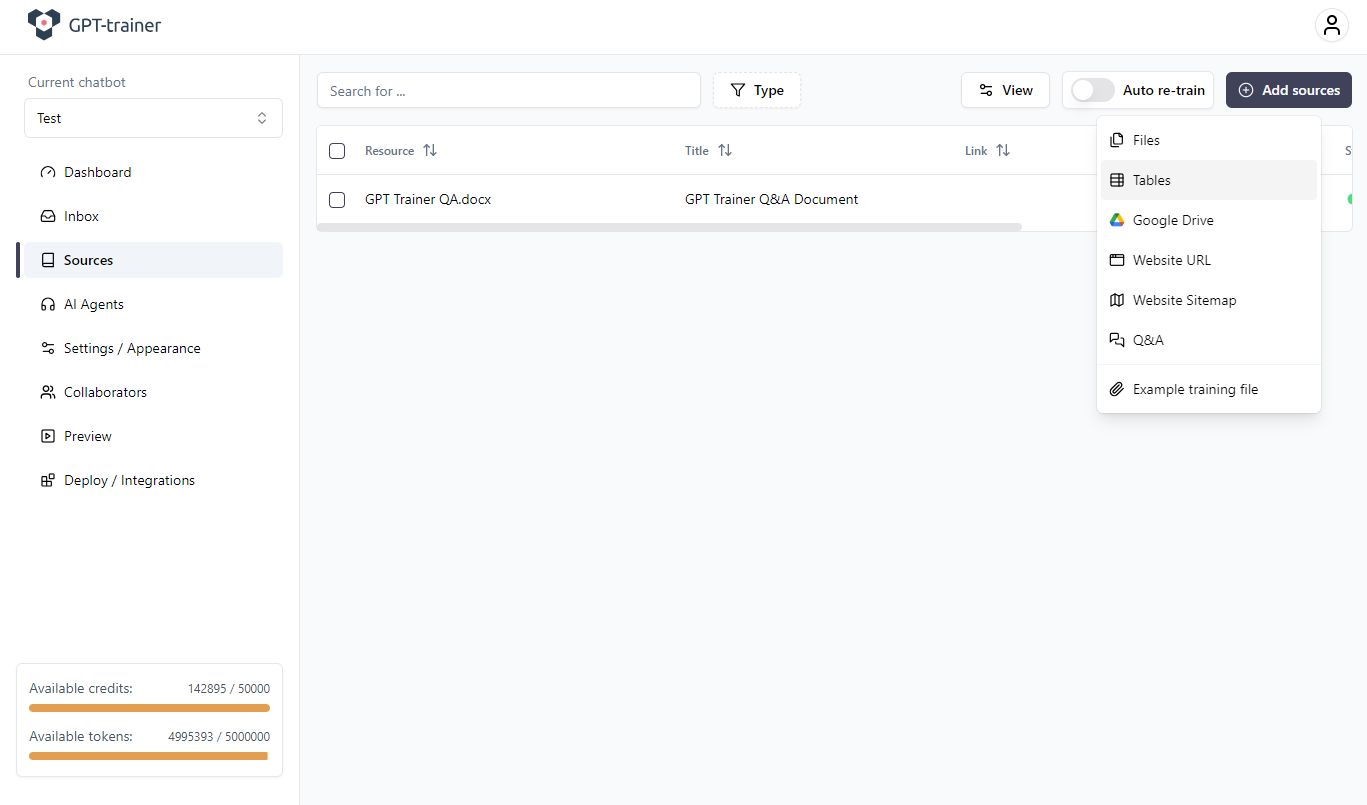
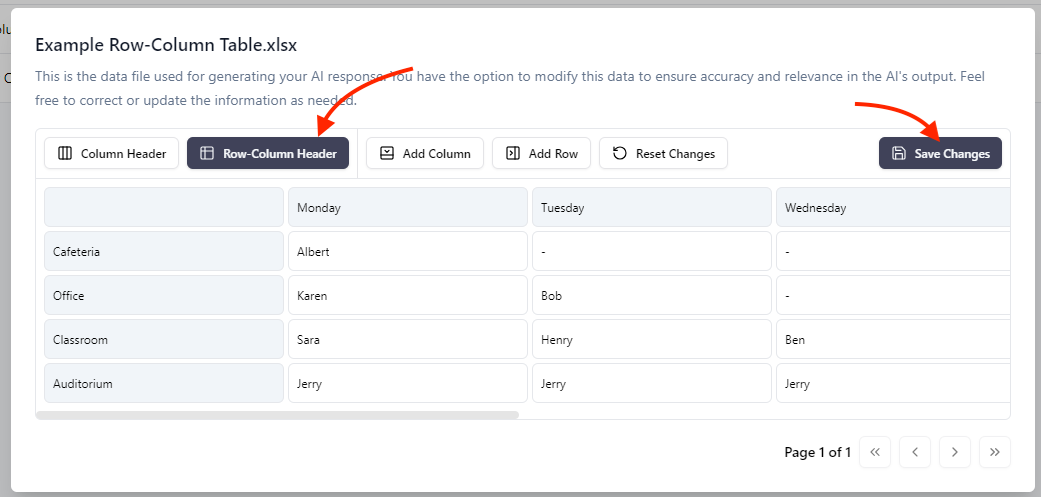
- Waehlen Sie die Tabelle aus
- Oeffnen Sie das Drei-Punkte-Menue rechts
- Klicken Sie auf Edit Table Data

Dies stellt sicher, dass die Daten korrekt für LLM-Verarbeitung vorverarbeitet werden.
GPT-4-Modelle übertreffen GPT-3.5-Modelle deutlich hinsichtlich Praezision und Konsistenz beim Arbeiten mit Tabellen.
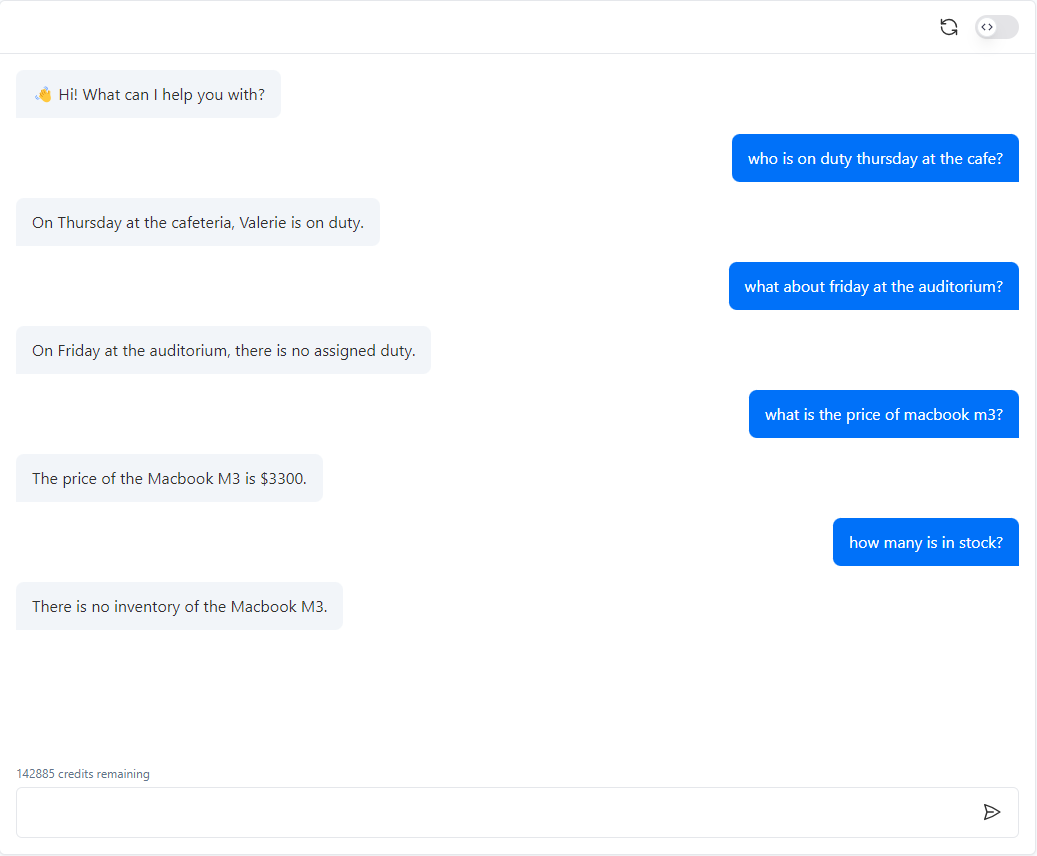
Mein Agent oder Chatbot versteht meine Tabelle nicht korrekt!
LLMs wie GPT-4 sind hervorragend im Umgang mit unstrukturiertem Text.Mit multimodaler Faehigkeit (z. B. GPT-Vision) koennen sie sogar Bilder interpretieren.
Tabellen sind jedoch etwas voellig anderes. Es gibt keine universelle Syntax zur Darstellung strukturierter Informationen.
Da LLMs probabilistisch arbeiten, sind sie nicht natürlich gut darin, tabellarische Daten direkt zu interpretieren. Ein Artikel der Microsoft Research analysiert die Leistungsfaehigkeit von GPT-4 bei strukturierten Daten: https://www.microsoft.com/en-us/research/blog/improving-llm-understanding-of-structured-data-and-exploring-advanced-prompting-methods/

Quelle: Microsoft Research INNOCHAT verwendet derzeit eine JSON-basierte Struktur, um Tabellen abzubilden.
Das ist nicht perfekt, unterstuetzt aber eine begrenzte Anzahl von Anwendungsfaellen, in denen Tabellen als Trainingsquelle verwendet werden. Wir wissen, dass viele Anwendungsfaelle groessere, komplexere und dynamische Datensaetze beinhalten.
Die statische Tabellenfunktion ist dafuer nicht optimal geeignet. Dafür empfehlen wir statt dessen Function Calling. Der robusteste und professionellste Ansatz für Retrieval-Augmented Generation (RAG) mit strukturierten Daten ist:
→ Function Calling mit SQL-basierten Custom Functions
Das heisst:- Sie entwerfen eigene Funktionen
- Die Funktionen beinhalten template-basierte SQL-Abfragen
- Daten werden dynamisch abgerufen
- Der Chatbot erhaelt die Ergebnisse als RAG-Kontext in Echtzeit
- etwas Programmiererfahrung
- Hosting Ihrer eigenen Serverfunktionen