Es bildete die Grundlage fuer neuartige neuronale Netzwerke zur Verarbeitung und zum Verstaendnis natuersslicher Sprache. Kurz darauf popularisierte OpenAI die GPT-Modelle und leitete mit ChatGPT die Aera der Large Language Models (LLMs) ein.
Die dialogfaehige Leistung dieser Modelle hat viele Menschen glauben lassen, dass KI kurz davor sei, menschliche Intelligenz zu erreichen. Doch trotz ihres „menschlichen“ Verhaltens sehen, interpretieren und verstehen LLMs die Welt nicht wie Menschen.
Sie sind keine logischen Denkmaschinen, sondern eher probabilistische Konversationssimulatoren.
Ihr Verhalten basiert auf Mustererkennung und semantischen Korrelationen, nicht auf Logik oder Verstehen. INNOCHAT wird von OpenAI-LLMs betrieben und nutzt Retrieval Augmented Generation (RAG), um Antworten anhand Ihrer hochgeladenen Daten anzupassen.
Was ist Retrieval Augmented Generation (RAG)?
LLMs werden mit riesigen Textmengen trainiert.Sie erkennen Muster und generieren neue Texte basierend auf der Wahrscheinlichkeit, dass bestimmte „Tokens“ (Worte oder Wortteile) aufeinander folgen. Daher nennt OpenAI viele Endpunkte Chat Completions – das Modell „vollendet“ den Prompt.
Eine ausfuehrliche Erklaerung zu Tokens finden Sie in der offiziellen OpenAI-Dokumentation:
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
LLMs koennen sehr leicht halluzinieren, wenn keine relevanten Daten vorliegen. RAG versucht dieses Problem zu loesen, indem es dem Prompt zusaetzlichen Kontext hinzufuegt, der die Wahrscheinlichkeiten beeinflusst.
Beispiel
Prompt ohne Kontext:Der Kontext beeinflusst die Token-Generierung und fuehrt zu einer praeziseren Antwort. Das ist RAG: Der Prompt wird mit relevanten Wissensquellen angereichert, ohne das Modell selbst zu veraendern.
Warum füttern wir nicht einfach alle Daten auf einmal?
Weil Tokenlimits existieren. Ein OpenAI-Modell wie gpt-3.5-16k kann etwa 10.000 Woerter als Kontext aufnehmen.Ihre Wissensbasis besteht oft aus Hunderten Seiten oder Tausenden Dokumenten – also weit mehr als in ein einziges LLM-Fenster passt. Deshalb:
- Dokumente werden in Chunks geteilt
- Jeder Chunk wird „eingebettet“ (Embedding)
- Embeddings werden in einer Vektordatenbank gespeichert
- Bei jeder Nutzeranfrage werden die relevantesten Chunks gesucht
- Diese werden in den Prompt eingefuegt
- Das LLM antwortet auf Basis dieses kontextualisierten Prompts
Aehnliche Saetze liegen im Vektorraum „naeher beieinander“. Eine gute Einfuehrung in Embeddings:
https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
Beispiel: Anfrage „What is innoChat?“
Der relevanteste Chunk ist: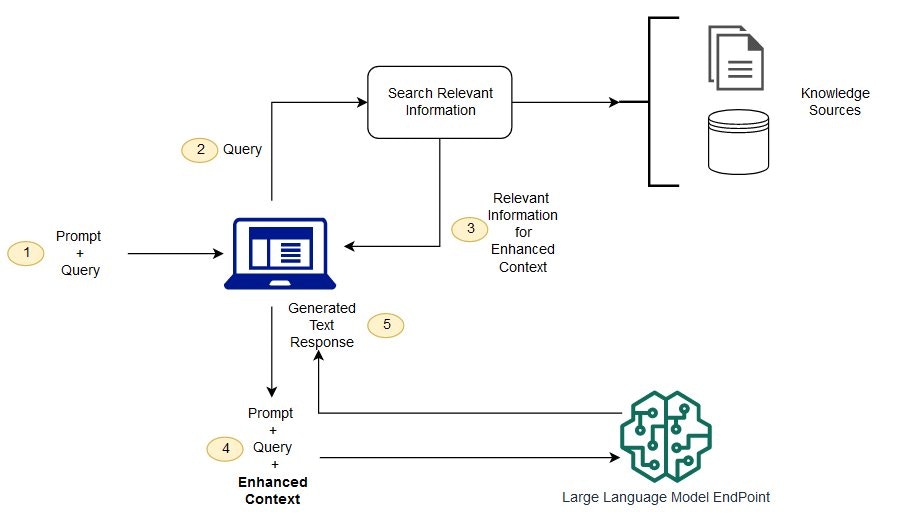
Welche Typen von Anfragen funktionieren gut?
Welche Typen von Anfragen funktionieren schlecht?
Wenn Ihr Anwendungsfall diese komplexeren Aufgaben verlangt, koennen Sie:
- Multi-Agent-Architektur
- Function Calling
Moeglicherweise koennen Sie die Leistung Ihres Chatbots verbessern, indem Sie Ihre Trainingsdaten optimieren.
Lesen Sie hierzu: 👉 Best practices for preparing training data