- Qualitaet Ihrer Trainingsdaten
- Auswahl des Large Language Models (LLM)
- Klarheit und Ausdruecklichkeit des Base Prompts
Wie in der AI-Forschung oft gesagt wird: „Ein Modell ist nur so gut wie seine Trainingsdaten.“ Die beste Moeglichkeit, die Leistung Ihres Chatbots zu optimieren, besteht darin, seine Trainingsdaten aufzuraeumen.
Im Folgenden geben wir wichtige Best Practices zur Strukturierung Ihrer Trainingsdaten. LLMs „denken“ nicht wie Menschen. Sie interpretieren Informationen anders.
Um zu verstehen, wie Daten verarbeitet werden, konzentrieren wir uns hier auf das Konzept der Chunks.
Chunk Splitting
Beim Retrieval-Augmented Generation (RAG) werden Chunks aus Ihrem Trainingsmaterial gewaehlt und gemeinsam mit dem Base Prompt in die Nutzeranfrage eingefuegt.Diese Chunks stammen direkt aus Ihren hochgeladenen Daten: PDFs, Webseiten, Word-Dokumente, TXT-Dateien usw. Da LLMs Tokenlimits haben, muessen wir die Groesse eines Chunks begrenzen. Das bedeutet:
- Selbst wenn ein Kapitel Ihres Dokuments ein einziges Thema behandelt,
muss es in mehrere Chunks aufgeteilt und separat in unserer Vektordatenbank gespeichert werden.
INNOCHAT nutzt eine Kombination aus regelbasierten und statistischen Algorithmen zur Chunk-Erstellung, doch wir koennen nicht garantieren, dass jeder Chunk:
- vollstaendig,
- sauber,
- grammatikalisch korrekt
- oder semantisch konsistent ist.
Chunk-Qualitaet
Eine weitere Fehlerquelle ist der Inhalt des Chunks selbst. Optimalerweise ist jeder Chunk:- selbstaendig interpretierbar
- semantisch konsistent
- grammatikalisch richtig
- mit optionaler Metadatenangabe (Position im Dokument)
- Browser rendern Webseiten anders als Web-Scraper sie sehen
- Layout, Bilder, Illustrationen oder eingebettete Inhalte gehen oft verloren
- Tabellen koennen verzerrt dargestellt werden
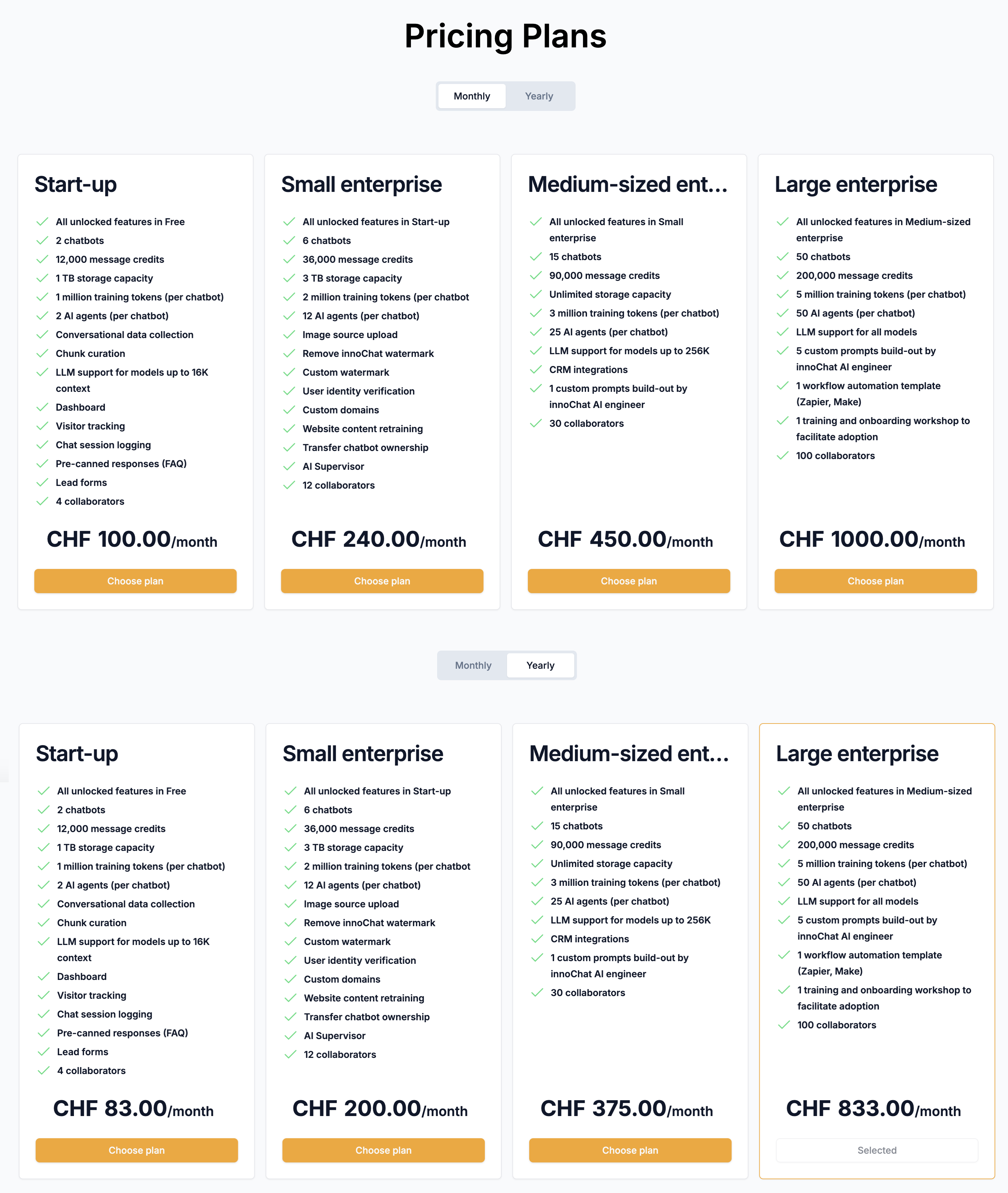
No gaps, no overlaps
RAG funktioniert, indem es eine Teilmenge relevanter Chunks aus Ihren Trainingsdaten waehlt.Dazu wird:
- Die Nutzeranfrage eingebettet
- Jeder Chunk ebenfalls eingebettet
- Die Aehnlichkeit berechnet (cosine distance)
- Die Top-n-Chunks ausgewaehlt (abhängig vom Tokenlimit des gewaehlten Modells)
- dass mehrere Chunks das gleiche Thema betreffen
- aber faktisch unterschiedliche oder widerspruechliche Informationen enthalten
[Chunk 1] iPhone SE’s current price is $250. [Chunk 2] Original iPhone SE is $199. [Chunk 3] iPhone 5’s price is $600.Alle Chunks sind semantisch relevant – sie enthaelt den Begriff „iPhone SE“.
Aber die Fakten sind uneinheitlich.
Dies fuehrt zu inkonsistenten Chatbot-Antworten, selbst bei identischen Fragen.
Empfehlung: MECE-Prinzip
Mutually Exclusive, Collectively Exhaustive= keine Ueberschneidungen, keine Luecken. Strukturieren Sie Ihre Trainingsdaten so, dass:
- Informationen klar abgegrenzt sind
- keine widerspruechlichen Aussagen existieren
Entfernen Sie unnötige Trainingsdaten
RAG ist ein semantischer Matching-Prozess.Da LLMs Tokenlimits haben, kann nur ein kleiner Teil des Wissensspeichers pro Anfrage verwendet werden. Beispiel:
- 20 Chunks insgesamt
- 10 Chunks pro Anfrage verfuegbar
→ Jede Anfrage deckt 50 % der Wissensbasis ab
- 2000 Chunks insgesamt
- 10 Chunks pro Anfrage verfuegbar
→ Jede Anfrage nutzt nur 0.5 % der Wissensbasis