Le “tabelle semplici” si riferiscono a dati tabellari senza celle unite, con un’unica colonna di chiave primaria con elementi univoci, intestazioni di colonne o righe univoche e descrittive e una chiara struttura a colonne oppure righe/colonne. Esempio di tabella solo a colonne:
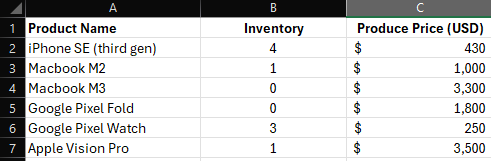

Se viene superato, il training va in errore. Al marzo 2024, il massimo è circa 8000 token per riga (incluso il codice JSON necessario per rappresentare la struttura della tabella).
Ciò significa che la quota effettivamente disponibile per i valori è inferiore e dipende dalla lunghezza dei nomi di righe e colonne. Se i tuoi dati rispettano il formato descritto sopra, puoi caricare la tabella come fonte di training.
Per farlo, vai su: Sources → Add Sources → Tables
- Seleziona la tabella
- Apri il menu a tre punti sulla destra
- Fai clic su Edit Table Data

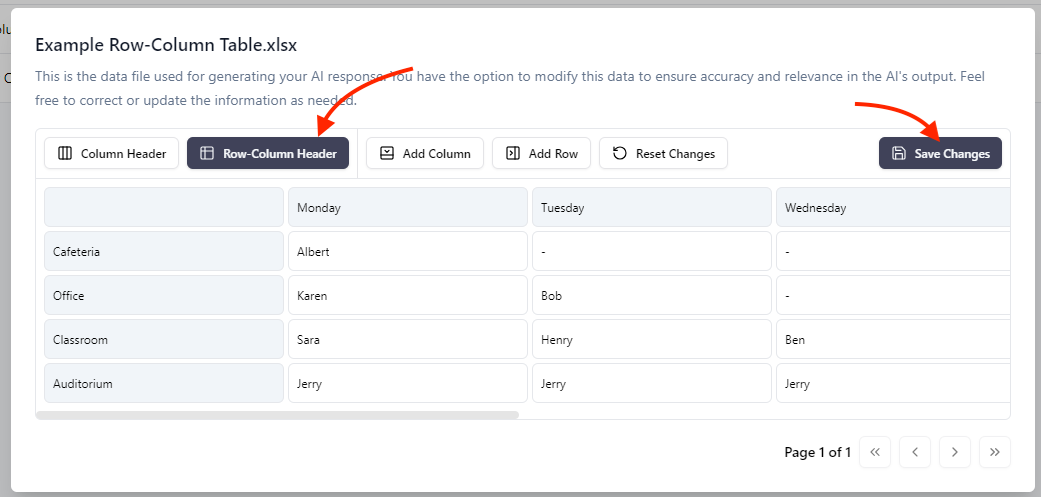
Questo assicura che i dati vengano pre-elaborati correttamente per l’elaborazione da parte del LLM.
I modelli GPT-4 superano nettamente i modelli GPT-3.5 in termini di precisione e coerenza quando si lavora con le tabelle.
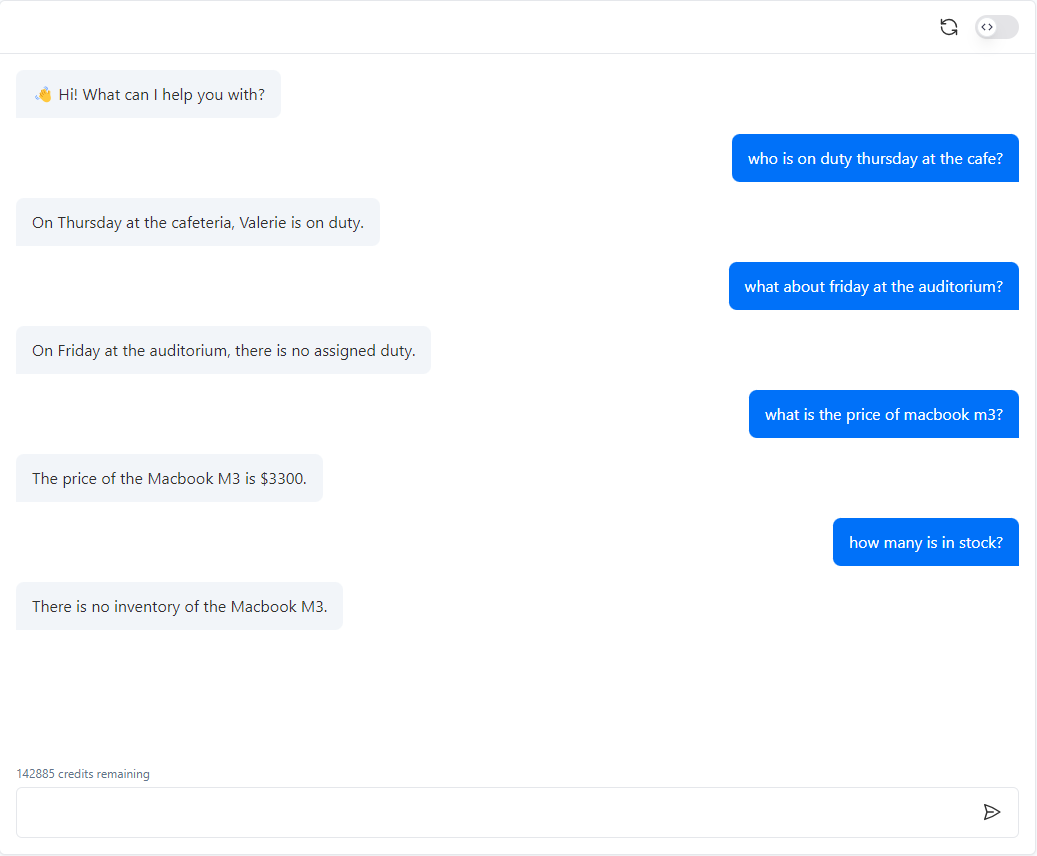
Il mio agente o chatbot non comprende correttamente la mia tabella!
I LLM come GPT-4 sono eccellenti nel gestire testo non strutturato.Con capacità multimodali (ad es. GPT-Vision) possono persino interpretare immagini.
Le tabelle, però, sono tutt’altra cosa. Non esiste una sintassi universale per rappresentare informazioni strutturate.
Poiché i LLM funzionano in modo probabilistico, non sono naturalmente bravi a interpretare direttamente dati tabellari. Un articolo di Microsoft Research analizza le prestazioni di GPT-4 con dati strutturati: https://www.microsoft.com/en-us/research/blog/improving-llm-understanding-of-structured-data-and-exploring-advanced-prompting-methods/

Fonte: Microsoft Research INNOCHAT utilizza attualmente una struttura basata su JSON per rappresentare le tabelle.
Non è perfetta, ma supporta un numero limitato di casi d’uso in cui le tabelle vengono utilizzate come fonte di training. Sappiamo che molti casi d’uso includono dataset più grandi, più complessi e più dinamici.
La funzione di tabelle statiche non è ideale per questo. Per questo motivo, consigliamo invece il Function Calling. L’approccio più robusto e professionale per la Retrieval-Augmented Generation (RAG) con dati strutturati è:
→ Function Calling con Custom Functions basate su SQL
Questo significa:- Progetti le tue funzioni
- Le funzioni includon