- Qualità dei tuoi dati di addestramento
- Scelta del Large Language Model (LLM)
- Chiarezza ed esplicitezza del prompt di base
Come si dice spesso nella ricerca sull’IA: «Un modello è buono quanto i suoi dati di addestramento.» Il modo migliore per ottimizzare le prestazioni del tuo chatbot consiste nel ripulire i suoi dati di addestramento.
Di seguito trovi le best practices più importanti per strutturare i tuoi dati di addestramento. Gli LLM non «pensano» come gli esseri umani. Interpretano le informazioni in modo diverso.
Per capire come vengono elaborate le informazioni, ci concentriamo qui sul concetto di chunk.
Suddivisione in chunk (Chunk Splitting)
Nel Retrieval-Augmented Generation (RAG), vengono selezionati dei chunk dal tuo materiale di addestramento e inseriti insieme al prompt di base nella richiesta dell’utente.Questi chunk provengono direttamente dai tuoi dati caricati: PDF, pagine web, documenti Word, file TXT, ecc. Dato che gli LLM hanno limiti di token, dobbiamo limitare la dimensione di un chunk. Ciò significa:
- Anche se un capitolo del tuo documento tratta un unico argomento,
deve essere suddiviso in più chunk e memorizzato separatamente nel nostro database vettoriale.
INNOCHAT utilizza una combinazione di algoritmi basati su regole e statistici per creare i chunk, ma non possiamo garantire che ogni chunk sia:
- completo,
- pulito,
- grammaticalmente corretto,
- o semanticamente coerente.
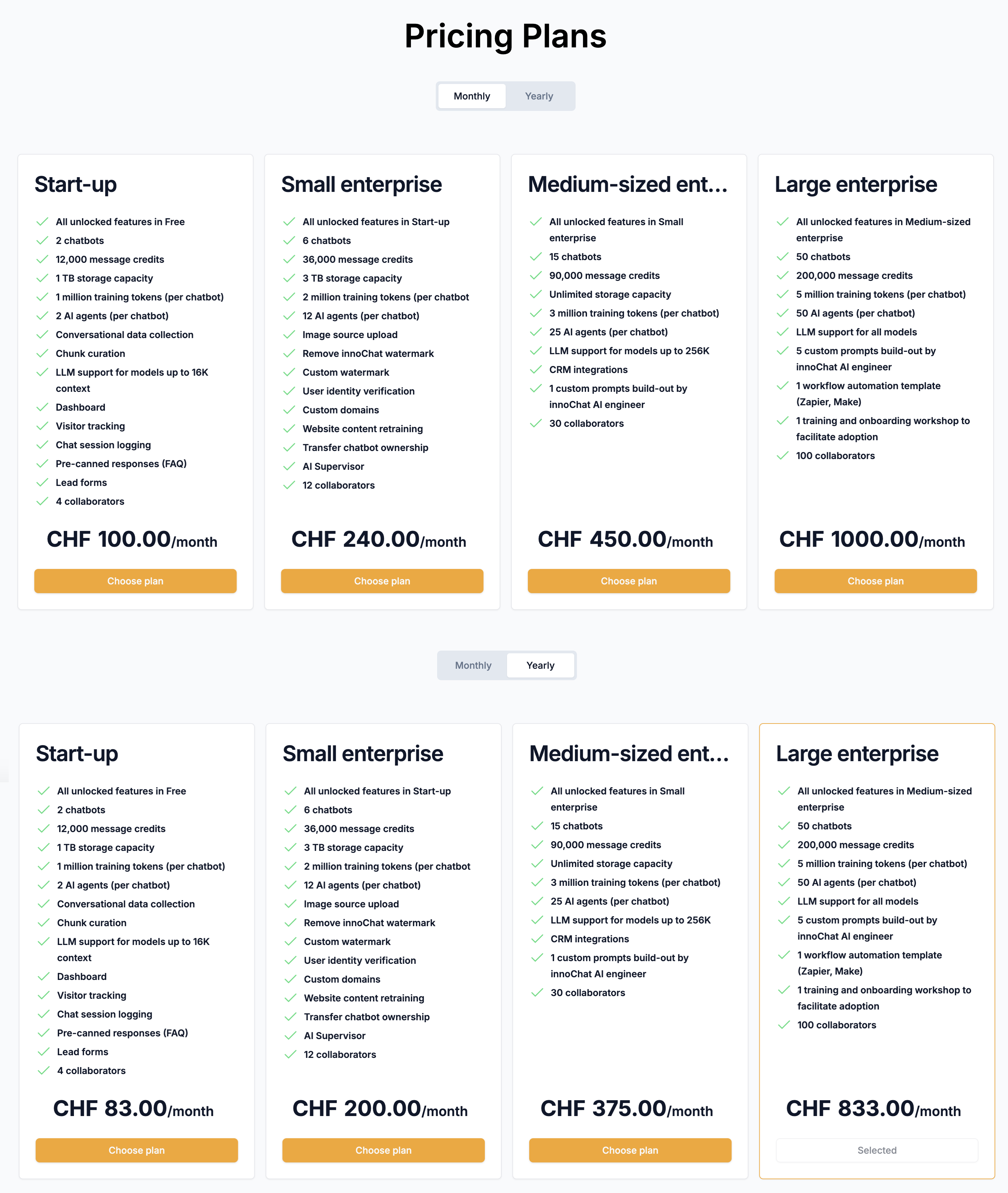
Qualità dei chunk
Un’altra fonte di errore è il contenuto del chunk stesso. Idealmente, ogni chunk dovrebbe essere:- interpretabile in modo autonomo
- semanticamente coerente
- grammaticalmente corretto
- con eventuale indicazione di metadati (posizione nel documento)
- I browser visualizzano le pagine in modo diverso rispetto a un web-scraper
- Layout, immagini, illustrazioni o contenuti incorporati spesso vanno persi
- Le tabelle possono risultare distorte
No gaps, no overlaps
Il RAG funziona selezionando un sottoinsieme di chunk rilevanti dai tuoi dati di addestramento.Per farlo:
- La richiesta dell’utente viene incorporata (embedded)
- Ogni chunk viene incorporato
- Viene calcolata la similarità (distanza coseno)
- Vengono selezionati i Top-n chunk (in base al limite di token del modello scelto)
- più chunk riguardino lo stesso argomento
- ma contengano informazioni fattualmente diverse o contraddittorie
[Chunk 1] Il prezzo attuale dell’iPhone SE è di $250. [Chunk 2] L’iPhone SE originale costa $199. [Chunk 3] Il prezzo dell’iPhone 5 è di $600.Tutti i chunk sono semanticamente rilevanti – contengono il termine «iPhone SE».
Ma i fatti sono incoerenti.
Ciò porta a risposte incoerenti del chatbot, anche per domande identiche.
Raccomandazione: Principio MECE
Mutually Exclusive, Collectively Exhaustive= nessuna sovrapposizione, nessuna lacuna. Struttura i tuoi dati di addestramento in modo che:
- le informazioni siano chiaramente delimitate
- non esistano affermazioni contraddittorie
Rimuovi i dati di addestramento non necessari
Il RAG è un processo di corrispondenza semantica.Dato il limite di token degli LLM, solo una piccola parte della base di conoscenza può essere utilizzata per richiesta. Esempio:
- 20 chunk totali
- 10 chunk disponibili per richiesta
→ Ogni richiesta copre il 50 % della base di conoscenza
- 2000 chunk totali
- 10 chunk disponibili per richiesta
→ Ogni richiesta utilizza solo lo 0,5 % della base di conoscenza