Ha costituito la base per nuove reti neurali dedicate al processamento e alla comprensione del linguaggio naturale. Poco dopo, OpenAI ha reso popolari i modelli GPT e, con ChatGPT, ha inaugurato l’era dei Large Language Models (LLM).
Le prestazioni conversazionali di questi modelli hanno fatto credere a molti che l’IA fosse sul punto di raggiungere l’intelligenza umana. Tuttavia, nonostante il loro comportamento “umano”, gli LLM non vedono, interpretano né comprendono il mondo come gli esseri umani.
Non sono macchine logiche di ragionamento, ma piuttosto simulatori conversazionali probabilistici.
Il loro comportamento si basa sul riconoscimento di pattern e sulle correlazioni semantiche, non sulla logica o sulla comprensione. INNOCHAT è alimentato dai LLM di OpenAI e utilizza la Retrieval Augmented Generation (RAG) per adattare le risposte in base ai dati caricati dall’utente.
Che cos’è la Retrieval Augmented Generation (RAG)?
Gli LLM vengono addestrati su enormi quantità di testo.Riconoscono pattern e generano nuovo testo basandosi sulla probabilità che determinati «token» (parole o parti di parole) si susseguano. Per questo motivo OpenAI chiama molti dei suoi endpoint Chat Completions — il modello «completa» il prompt.
Una spiegazione dettagliata sui token è disponibile nella documentazione ufficiale OpenAI:
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
Gli LLM possono molto facilmente allucinare quando non dispongono di dati rilevanti. La RAG cerca di risolvere questo problema aggiungendo al prompt un contesto supplementare che influenza le probabilità.
Esempio
Prompt senza contesto:Ma cosa succede se il prompt diventa:
Il contesto influenza la generazione dei token e porta a una risposta molto più precisa. Questo è RAG: arricchire il prompt con fonti di conoscenza rilevanti, senza modificare il modello stesso.
Perché non inseriamo semplicemente tutti i dati in una volta?
Perché esistono limiti di token. Un modello OpenAI come gpt-3.5-16k può gestire circa 10.000 parole di contesto.La tua base di conoscenza spesso comprende centinaia di pagine o migliaia di documenti — molto più di quanto possa entrare in una singola finestra LLM. Ecco perché:
- I documenti vengono suddivisi in chunk
- Ogni chunk viene «incorporato» (embedding)
- Gli embedding vengono salvati in un database vettoriale
- A ogni richiesta utente vengono cercati i chunk più rilevanti
- Questi vengono inseriti nel prompt
- L’LLM risponde sulla base di questo prompt contestualizzato
Frasi simili si trovano «più vicine» nello spazio vettoriale. Una buona introduzione agli embedding:
https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
Esempio: query «What is innoChat?»
Il chunk più rilevante è: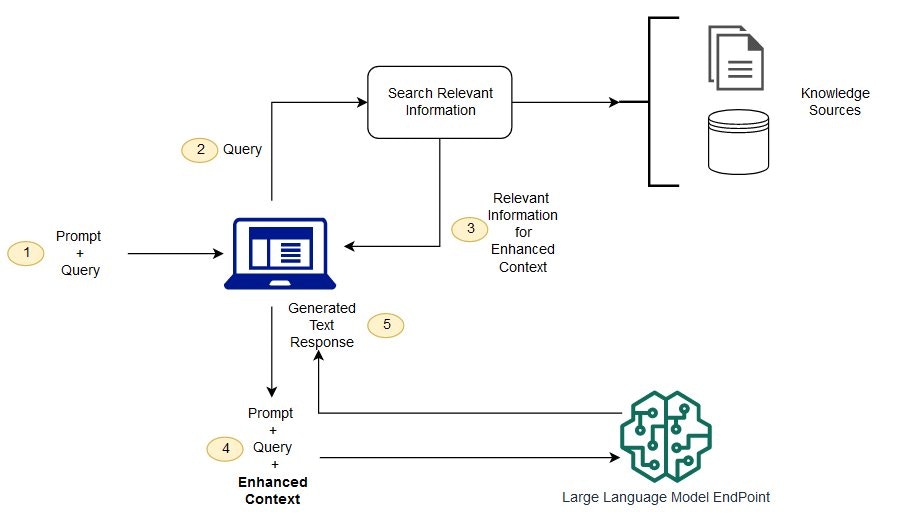
Quali tipi di domande funzionano bene?
Quali tipi di domande funzionano male?
Se il tuo caso d’uso richiede questi compiti più complessi, puoi utilizzare:
- un’architettura multi-agente
- il function calling
È possibile migliorare le prestazioni del tuo chatbot ottimizzando i dati di addestramento.
Leggi a riguardo: 👉 Best practices per la preparazione dei dati di addestramento