Les « tableaux simples » désignent des données tabulaires sans cellules fusionnées, avec une seule colonne de clé primaire contenant des éléments uniques, des en-têtes de colonnes ou de lignes uniques et explicites, ainsi qu’une structure claire colonne ou ligne/colonne. Exemple de tableau purement en colonnes :
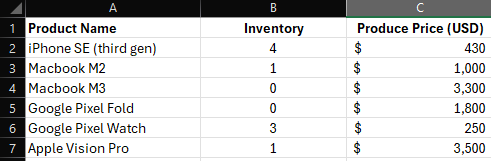

Si cette limite est dépassée, l’entraînement se termine par une erreur. À la date de mars 2024, le maximum est de ~8000 tokens par ligne (y compris le code JSON nécessaire pour représenter la structure du tableau).
Cela signifie que la part réellement disponible pour les valeurs est plus faible et dépend de la longueur des noms de colonnes et de lignes. Si vos données respectent le format décrit ci-dessus, vous pouvez importer votre tableau comme source d’entraînement.
Pour cela, allez dans : Sources → Add Sources → Tables
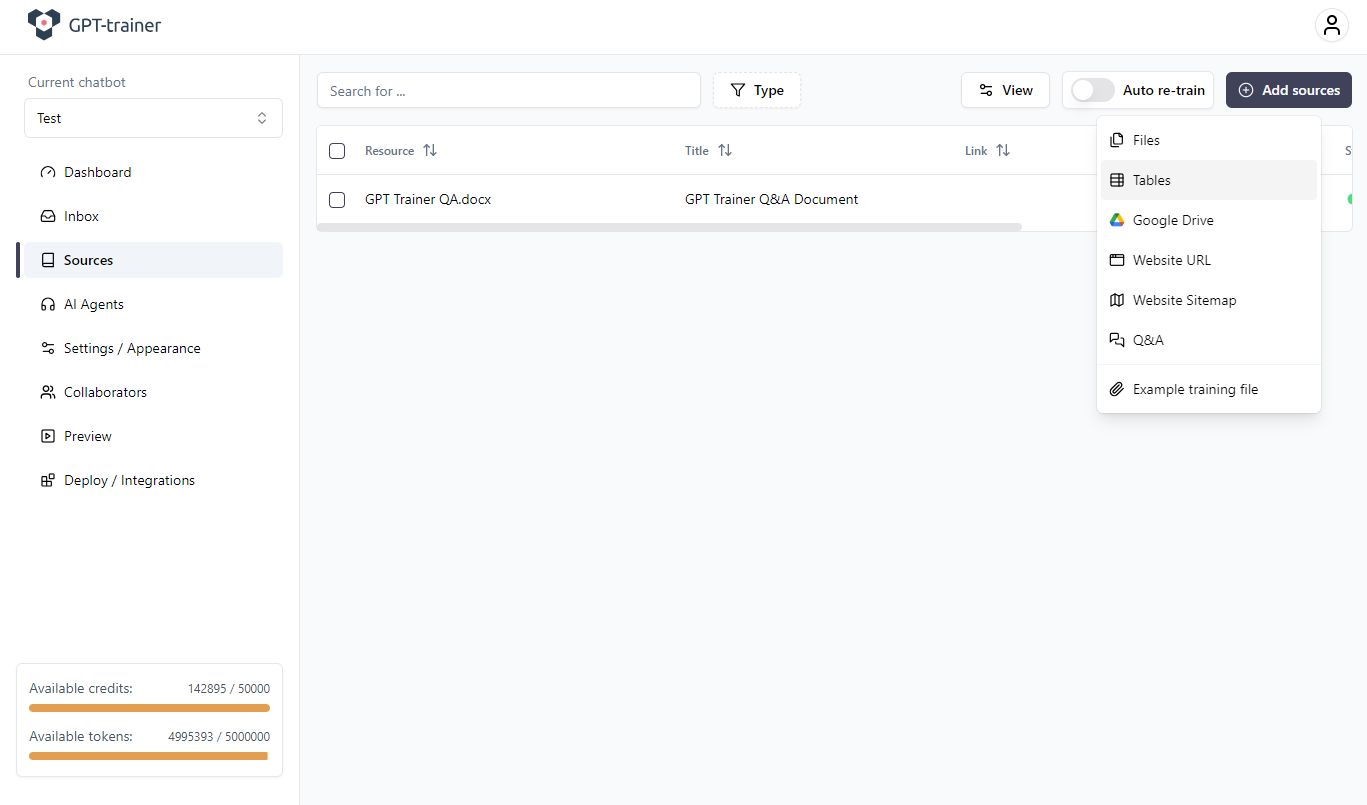
- Sélectionnez le tableau
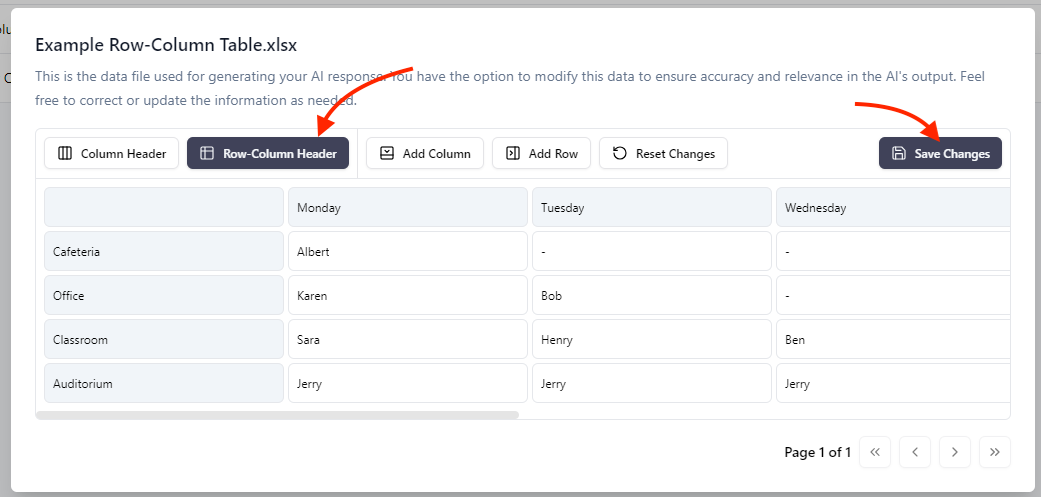
- Ouvrez le menu à trois points à droite
- Cliquez sur Edit Table Data

Cela garantit que les données sont correctement prétraitées pour le traitement par le LLM.
Les modèles GPT-4 surpassent largement les modèles GPT-3.5 en termes de précision et de cohérence lorsqu’il s’agit de travailler avec des tableaux.
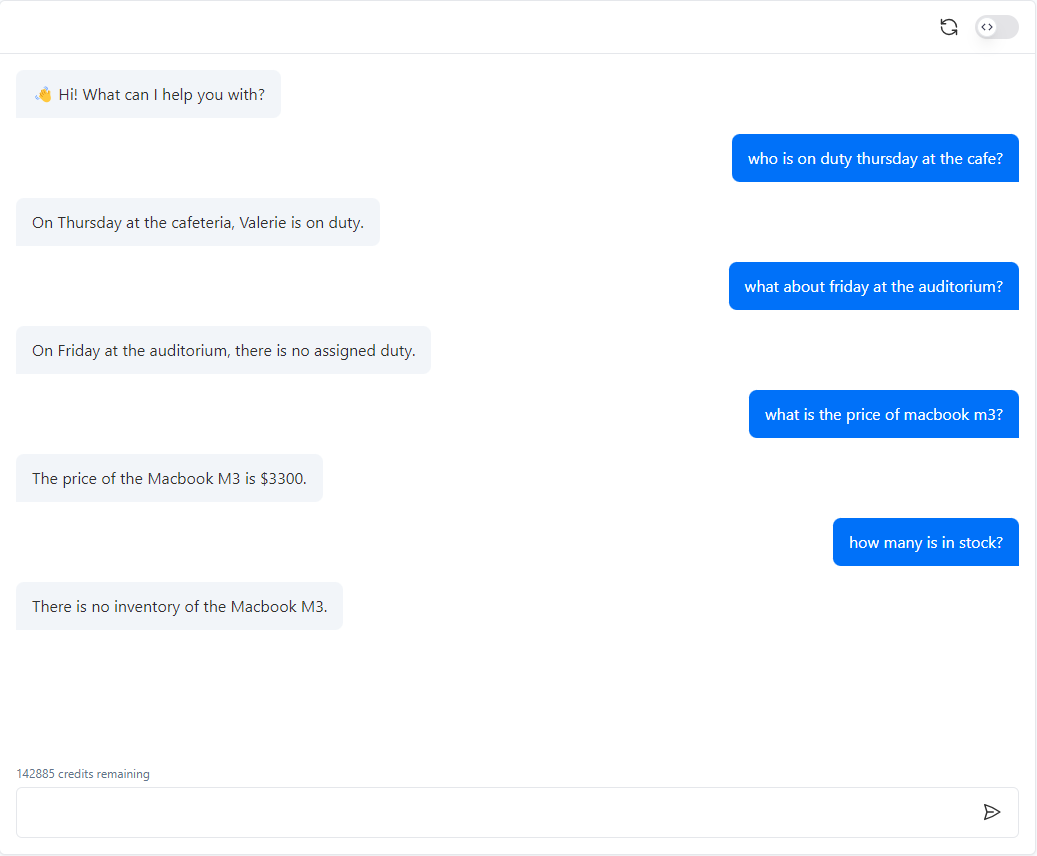
Mon agent ou chatbot ne comprend pas correctement mon tableau !
Les LLM tels que GPT-4 excellent dans le traitement du texte non structuré.Avec des capacités multimodales (par ex. GPT-Vision), ils peuvent même interpréter des images.
Les tableaux, en revanche, sont tout autre chose. Il n’existe aucune syntaxe universelle pour représenter des informations structurées.
Comme les LLM fonctionnent de manière probabiliste, ils ne sont pas naturellement doués pour interpréter directement des données tabulaires. Un article de Microsoft Research analyse les performances de GPT-4 sur des données structurées : https://www.microsoft.com/en-us/research/blog/improving-llm-understanding-of-structured-data-and-exploring-advanced-prompting-methods/

Source : Microsoft Research INNOCHAT utilise actuellement une structure basée sur JSON pour représenter les tableaux.
Ce n’est pas parfait, mais cela prend en charge un nombre limité de cas d’usage où les tableaux sont utilisés comme source d’entraînement. Nous savons que de nombreux cas d’usage impliquent des jeux de données plus grands, plus complexes et plus dynamiques.
La fonctionnalité de tableaux statiques n’est pas optimale pour cela. C’est pourquoi nous recommandons plutôt le Function Calling. L’approche la plus robuste et la plus professionnelle pour la Retrieval-Augmented Generation (RAG) avec des données structurées est :
→ Function Calling avec des Custom Functions basées sur SQL
Cela signifie :- Vous concevez vos propres fonctions
- Les fonctions contiennent des requêtes SQL basées sur des templates
- Les données sont récupérées de manière dynamique
- Le chatbot reçoit les résultats en tant que contexte RAG en temps réel
- un minimum d’expérience en programmation
- l’hébergement de vos propres fonctions côté serveur