- La qualité de vos données d’entraînement
- Le choix du Large Language Model (LLM)
- La clarté et l’explicité du prompt de base
Comme on le dit souvent dans la recherche en IA : « Un modèle n’est aussi bon que ses données d’entraînement. » La meilleure façon d’optimiser les performances de votre chatbot consiste à nettoyer ses données d’entraînement.
Voici les bonnes pratiques essentielles pour structurer vos données d’entraînement. Les LLMs ne « pensent » pas comme les humains. Ils interprètent les informations différemment.
Pour comprendre comment les données sont traitées, nous nous concentrons ici sur le concept des chunks.
Découpage en chunks (Chunk Splitting)
Dans le cadre du Retrieval-Augmented Generation (RAG), des chunks issus de votre matériel d’entraînement sont sélectionnés et insérés avec le prompt de base dans la requête de l’utilisateur.Ces chunks proviennent directement de vos données téléchargées : PDF, pages web, documents Word, fichiers TXT, etc. Étant donné que les LLMs ont des limites de tokens, nous devons limiter la taille d’un chunk. Cela signifie :
- Même si un chapitre de votre document traite d’un seul sujet,
il doit être divisé en plusieurs chunks et stocké séparément dans notre base de données vectorielle.
INNOCHAT utilise une combinaison d’algorithmes basés sur des règles et statistiques pour créer les chunks, mais nous ne pouvons pas garantir que chaque chunk soit :
- complet,
- propre,
- grammaticalement correct,
- ou sémantiquement cohérent.
Qualité des chunks
Une autre source d’erreur réside dans le contenu du chunk lui-même. Idéalement, chaque chunk devrait être :- interprétable de manière autonome
- sémantiquement cohérent
- grammaticalement correct
- avec éventuellement des métadonnées (position dans le document)
- Les navigateurs affichent les pages différemment de ce que voit un web-scraper
- La mise en page, les images, illustrations ou contenus embarqués sont souvent perdus
- Les tableaux peuvent être déformés
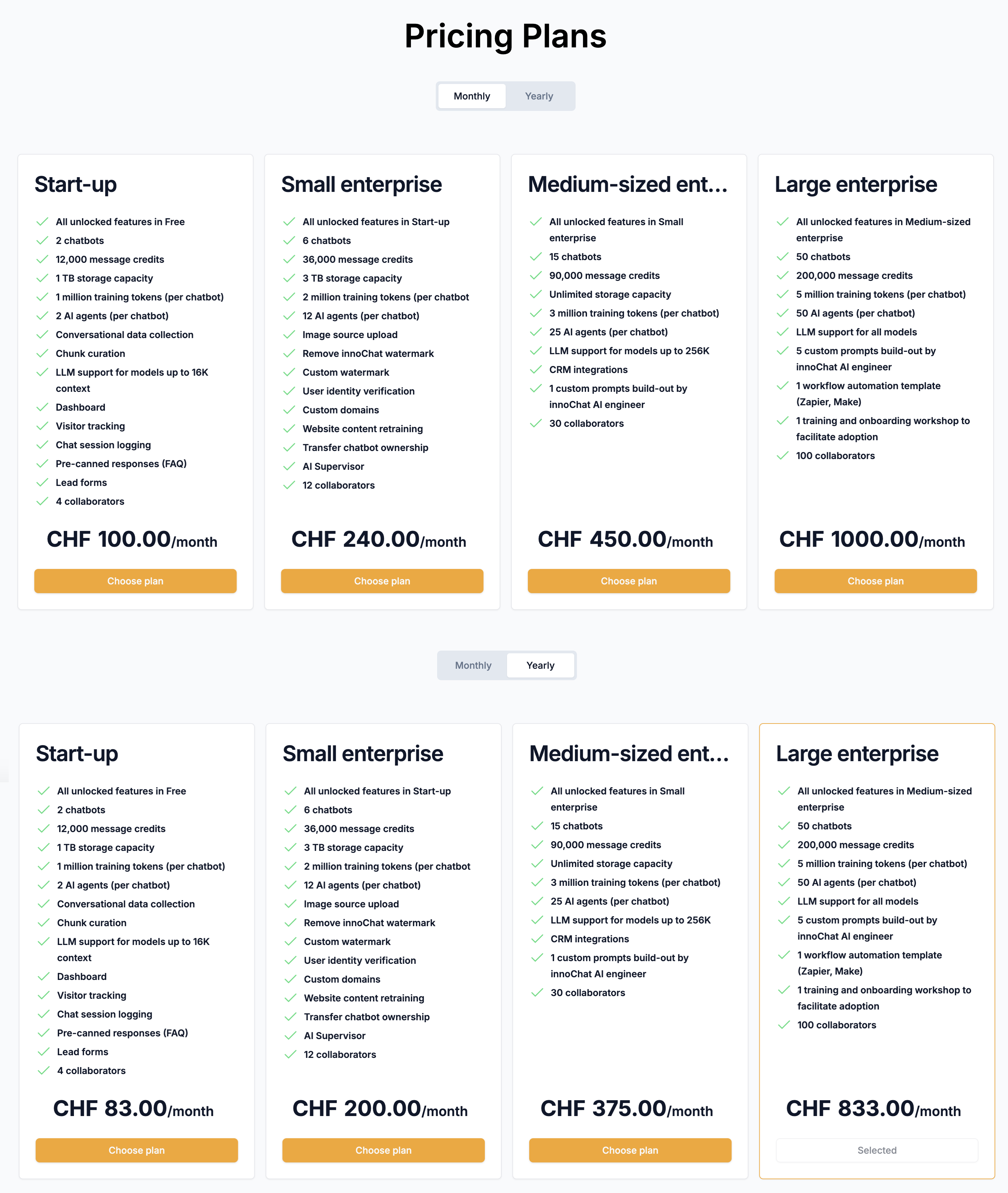
Pas de lacunes, pas de chevauchements
Le RAG fonctionne en sélectionnant un sous-ensemble de chunks pertinents parmi vos données d’entraînement.Pour cela :
- La requête de l’utilisateur est encodée (embedded)
- Chaque chunk est également encodé
- La similarité est calculée (distance cosinus)
- Les Top-n chunks sont sélectionnés (selon la limite de tokens du modèle choisi)
- que plusieurs chunks traitent du même sujet
- mais contiennent des informations factuellement différentes ou contradictoires
[Chunk 1] Le prix actuel de l’iPhone SE est de 250 $. [Chunk 2] L’iPhone SE original coûte 199 $. [Chunk 3] Le prix de l’iPhone 5 est de 600 $.Tous les chunks sont sémantiquement pertinents – ils contiennent le terme « iPhone SE ».
Mais les faits sont incohérents.
Cela entraîne des réponses incohérentes du chatbot, même pour des questions identiques.
Recommandation : Principe MECE
Mutually Exclusive, Collectively Exhaustive= pas de chevauchements, pas de lacunes. Structurez vos données d’entraînement de façon à ce que :
- les informations soient clairement délimitées
- il n’existe pas d’affirmations contradictoires
Supprimez les données d’entraînement inutiles
Le RAG est un processus de correspondance sémantique.Étant donné les limites de tokens des LLMs, seule une petite partie de la base de connaissances peut être utilisée par requête. Exemple :
- 20 chunks au total
- 10 chunks disponibles par requête
→ Chaque requête couvre 50 % de la base de connaissances
- 2000 chunks au total
- 10 chunks disponibles par requête
→ Chaque requête n’utilise que 0,5 % de la base de connaissances