Il a constitué la base de nouveaux réseaux neuronaux pour le traitement et la compréhension du langage naturel. Peu après, OpenAI a popularisé les modèles GPT et, avec ChatGPT, a lancé l’ère des Large Language Models (LLM).
Les performances conversationnelles de ces modèles ont conduit beaucoup de gens à croire que l’IA était sur le point d’atteindre l’intelligence humaine. Pourtant, malgré leur comportement « humain », les LLM ne voient, n’interprètent et ne comprennent pas le monde comme les humains.
Ce ne sont pas des machines à raisonner logiquement, mais plutôt des simulateurs conversationnels probabilistes.
Leur comportement repose sur la reconnaissance de motifs et les corrélations sémantiques, et non sur la logique ou la compréhension. INNOCHAT est propulsé par les LLM d’OpenAI et utilise la Retrieval Augmented Generation (RAG) pour adapter les réponses en fonction de vos données téléchargées.
Qu’est-ce que la Retrieval Augmented Generation (RAG) ?
Les LLM sont entraînés sur d’énormes quantités de texte.Ils reconnaissent des motifs et génèrent de nouveaux textes en se basant sur la probabilité que certains « tokens » (mots ou parties de mots) se suivent. C’est pourquoi OpenAI nomme beaucoup de ses endpoints Chat Completions — le modèle « complète » le prompt.
Une explication détaillée des tokens est disponible dans la documentation officielle OpenAI :
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
Les LLM peuvent très facilement halluciner lorsqu’aucune donnée pertinente n’est disponible. La RAG tente de résoudre ce problème en ajoutant au prompt un contexte supplémentaire qui influence les probabilités.
Exemple
Prompt sans contexte :Mais que se passe-t-il si le prompt devient :
Le contexte influence la génération des tokens et conduit à une réponse beaucoup plus précise. C’est cela la RAG : enrichir le prompt avec des sources de connaissance pertinentes, sans modifier le modèle lui-même.
Pourquoi ne pas simplement envoyer toutes les données en même temps ?
Parce qu’il existe des limites de tokens. Un modèle OpenAI comme gpt-3.5-16k peut gérer environ 10 000 mots de contexte.Votre base de connaissances comporte souvent des centaines de pages ou des milliers de documents — bien plus que ce qui rentre dans une seule fenêtre LLM. C’est pourquoi :
- Les documents sont découpés en chunks
- Chaque chunk est « encodé » (embedding)
- Les embeddings sont stockés dans une base de données vectorielle
- À chaque requête utilisateur, on recherche les chunks les plus pertinents
- Ces chunks sont insérés dans le prompt
- Le LLM répond sur la base de ce prompt contextualisé
Des phrases similaires se trouvent « plus proches » dans l’espace vectoriel. Une bonne introduction aux embeddings :
https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
Exemple : requête « What is innoChat ? »
Le chunk le plus pertinent est :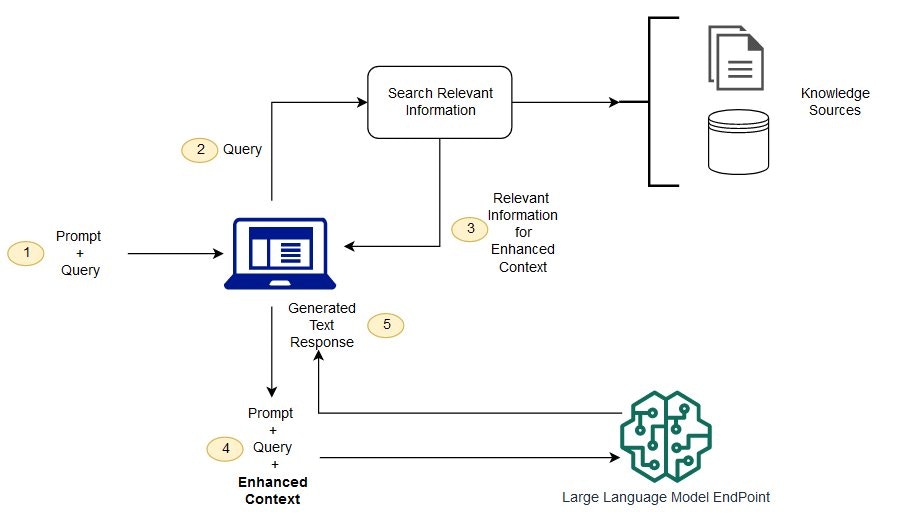
Quels types de questions fonctionnent bien ?
Quels types de questions fonctionnent mal ?
Si votre cas d’usage nécessite ces tâches plus complexes, vous pouvez utiliser :
- une architecture multi-agents
- le function calling
Il est possible d’améliorer les performances de votre chatbot en optimisant vos données d’entraînement.
Consultez à ce sujet : 👉 Bonnes pratiques pour la préparation des données d’entraînement